Atividade #1323
FechadaProjeto básico de redes neurais no código
Descrição
Visando o avanço do âmbito da inteligência artificial no mundo e nas competições, eu busquei implementar um código funcional no labview com um fps aceitável para verificar a compatibilidade do nosso código com algoritmos de IA.
Arquivos
{kind=link}
{kind=link}
{kind=link}
Atualizado por Felipe Welington há aproximadamente 6 anos
- Arquivo Gráficos.png Gráficos.png adicionado
Atualizado por Felipe Welington há aproximadamente 6 anos
- Descrição atualizado(a) (diff)
Atualizado por Felipe Welington há aproximadamente 6 anos
- Descrição atualizado(a) (diff)
Atualizado por Felipe Welington há aproximadamente 6 anos
- Descrição atualizado(a) (diff)
Atualizado por Gabriel Borges da Conceição há aproximadamente 6 anos
- Título alterado de Transmitir o conhecimento adquirido inteligência artificial no código para Projeto básico de redes neurais no código
Atualizado por Gabriel Borges da Conceição há aproximadamente 6 anos
- Atribuído para ajustado para Felipe Welington
Atualizado por Felipe Welington há aproximadamente 6 anos
- Descrição atualizado(a) (diff)
Atualizado por Felipe Welington há aproximadamente 6 anos
Nesse aspecto, cabe algumas explicações.
* Como linguagem de programação foi usado o Python, para tal eu usei a função python node do labview.
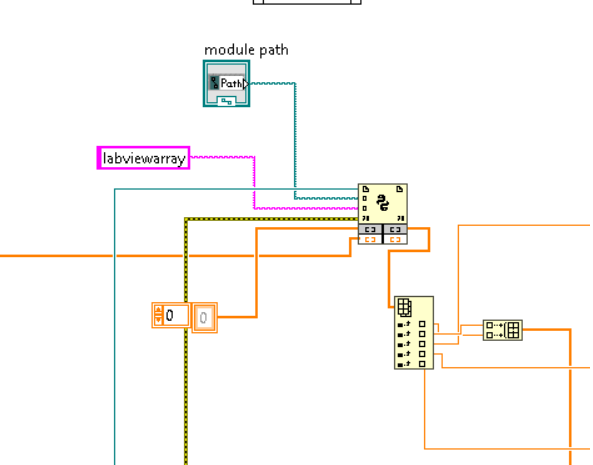
Ao rodar o código python pela primeira vez necessita que seu pc tenha uma versão do python compatível, após isso o labview cria um arquivo .cpython que é um "compilado" do código. Assim, após novamente usar o labview ele usa esse compilado, podendo ser usado em qualquer pc,mesmo que não tenha o python.
{{thumbnail(Compilado.png,size=600)}}O algoritmo que escolhi foi o de aprendizado por reforço, usando rede neurais e o objetivo seria a movimentação do robô
Na prática o algoritmo funciona como o aprendizado de uma criança, ele está em uma situação e coleta dados do ambiente, dai como qualquer criança ele erra e é punido com isso com uma recompensa negativa, por exemplo,
1. Se chocar com o robô inimigo
2. Se afastar demasiadamente do campo
3. Se afastar do objetivo
4. Chegar no objetivo com velocidade errada(atualmente no nosso código é sempre 0, mas para futuros plays pode ser diferente como um passe em movimento) ou orientação erradaAssim o código reformula os pesos, e ele vai aprendendo. O bom desse algoritmo é que há uma fase inicial de aprendizagem aonde eu coloco um gama alto, ou seja, alto nível de aprendizagem, isto é um erro faz ele se força a mudar de maneira expressiva. E quando ele estiver adulto, eu coloco um gama baixo que faz ele se adaptar durante o jogo, buscando melhorar, mas não se afastando muito do contorno.
Em tese, pensando em termos de cálculo, a fase de aprendizagem ele busca máximos locais, que façam ele aumentar sua recompensa, ou seja ser punido menos, e na fase de jogo nesse máximo ele busca o melhor ponto que se adequa ao jogo.
E o que ele tinha que fazer era coletar:
Os inputs
Largura do campo, comprimento do campo,Vxatual,Vyatual,Voatual,X,Y, Xbola, Ybola, Xinimigo1, Yinimigo1, Xinimigo2, Yinimigo2, Xobj, Yobj , Oobj.
E com isso me oferecer:
Os outputs
Vxdest,Vydest,Vodest{{thumbnail(Gráficos.png,size=600)}}Como se observa na imagem, eu retornei também alguns dados, como a distância e recompensa para ver como andava o treinamento do algoritmo.
Em tese, o código ficou incompleto porque falta eu criar alguns arquivos de escrita e leitura.
Dissertando agora sobre as vantagens.
Eu fiz o código em python, pois estou mais familiarizado com a linguagem, todavia escrevi ele com ajuda da biblioteca torch a qual se encontra no c++.
Com 1 robô em campo o fps sem restrições fica entre 110 e 150, todavia esse fps cria muitos erros no modelo, pois como há penalidades envolvida, se o código roda duas vezes e o robô não saiu do lugar ele será penalizado, entre outros. Assim na prática o código deveria rodar em sincronia com a comunicação beirando os 30 a 40 fps.
Na prática meu objetivo não era que esse algoritmo em si funcionasse, mas visar a possibilidade da inteligência artificial em conjunto com o nosso código, em âmbitos como skills, correção de erros, previsão de ação inimiga.
A princípio, eu obtive um resultado bem positivo, uma vez que modelos bem simples de treinamento podem ser criados de maneira a evitar códigos complexos no labview e podem obter resultados melhores.
Atualizado por Gabriel Borges da Conceição há aproximadamente 6 anos
Muito bom!
Fiquei com dúvida nessa parte "Em tese, o código ficou incompleto porque falta eu criar alguns arquivos de escrita e leitura", o que seriam e pra que serviriam esses arquivos e por que não os criou?
Foi dito que objetivo desse teste era fazer o robô se movimentar de um ponto a outro, deixe mais claro se alcançou esse objetivo ou não. Se não, o que faltou? O que fez dar errado e quais são os próximos passos?
Atualizado por Felipe Welington há aproximadamente 6 anos
Os arquivos de escrita e leitura são aonde ficaram armazenados os dados dos parâmetros da rede, tais como as recompensas e outros parametros de treinamento como estados anteriores. Nesse aspecto, faltou eu escolher o melhor tipo de arquivo para essa tarefa, sendo que também vale ressaltar a escolha do quanto será armazenado , atualmente são 1000 estados e para treinamento são usados 50.
O robô em um primeiro momento começa a ir para o objetivo, contudo depois de muitas horas a rede converge para as extremidades, pois qnd ela acha esse ponto de max , as recompensas ficam recorrentes e como ela n sai do lugar a rede meio que não consegue reagir a isso. Na prática, uma maneira de evitar isso é fazer um treinamento supervisionado da rede tendo como base o nosso código para que ao iniciar o aprendizado por reforço a rede não sair do 0 e sim de um ponto que permita ela chegar nos objetivos e ir se otimizando.
Atualizado por Antonio de Souza Gomes Pereira há mais de 4 anos
- Situação alterado de Em andamento para Fechada